前言
2022的log4j2shell爆发的时候还在高中,没亲身经历过,但这次实实在在亲历了一次互联网大核弹漏洞的发生,因为刚比赛回校又一堆作业和考试,没有赶上这波热潮,只能等潮水褪去后寒假回家自己复现学习学习
环境搭建
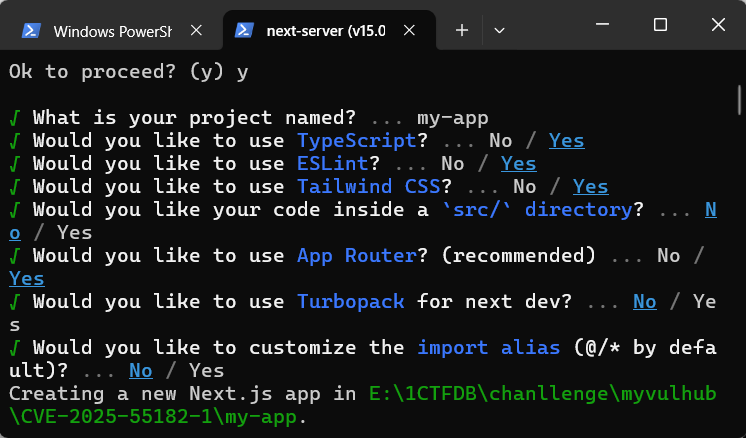
1 | npx create-next-app@15.0.4 |

warn就代表版本对了
然后配置全选默认
POC
1 | POST / |
调试环境配置
启动参数
1 | $env:NODE_OPTIONS="--inspect" |
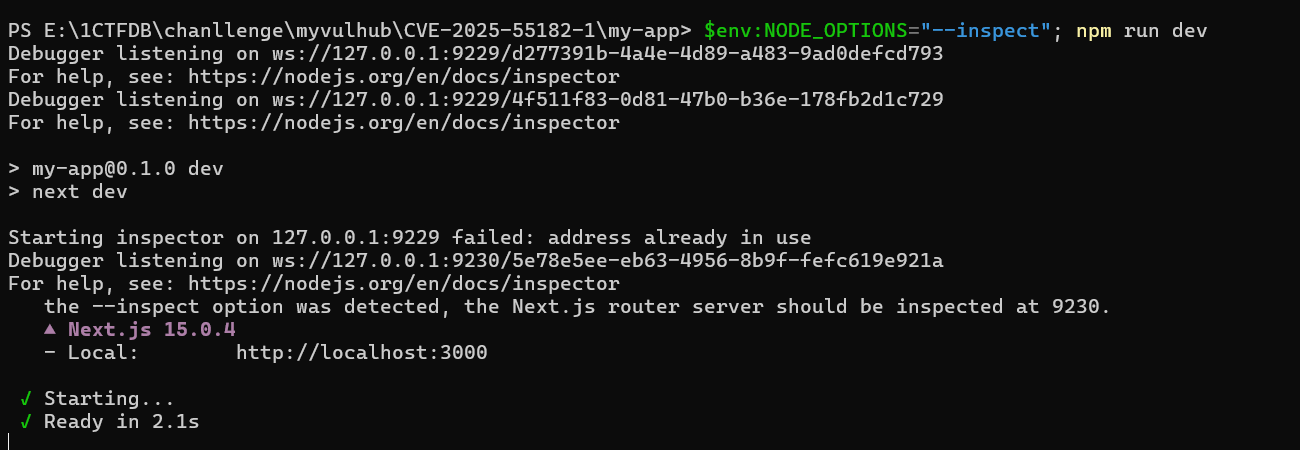
- 3000:Web应用的端口
- 9229:dev服务器守护进程的调试端口
- 9230:应用进程的调试端口
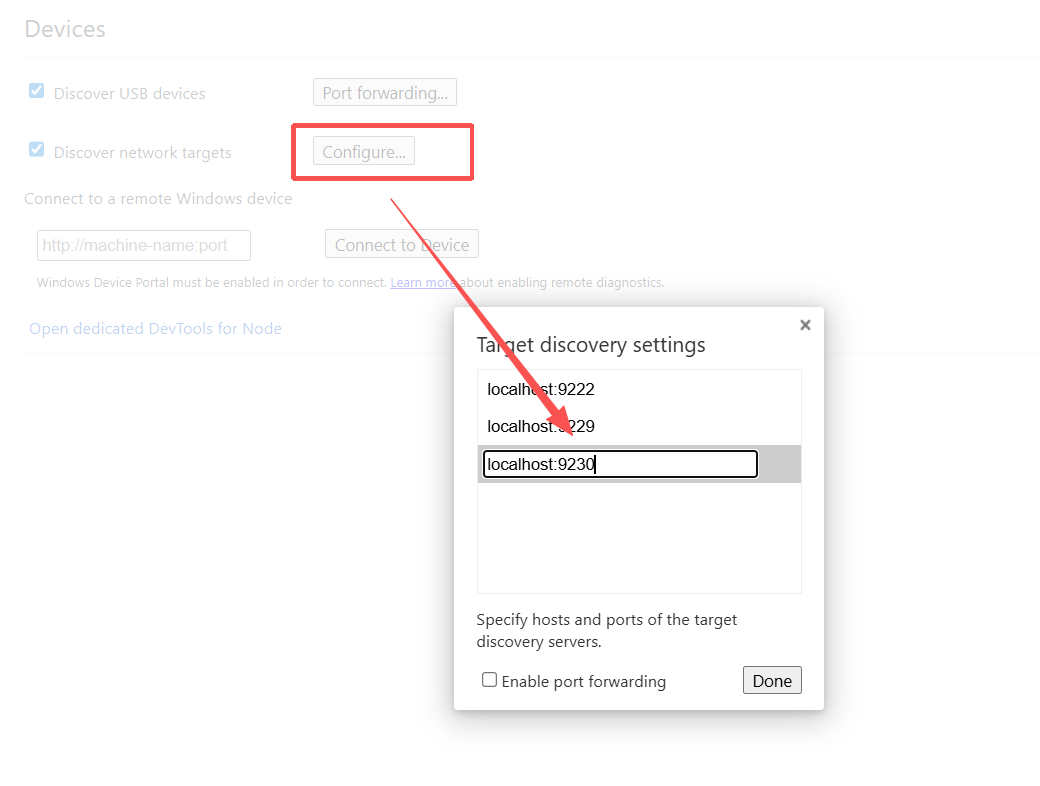
浏览器输入
1 | edge://inspect |
填入9230端口
然后让浏览器加载node_modules中的source map
将下面两个选项取消勾选
在这个Node.js的专用开发工具就可以看到源码进行调试了
漏洞分析
因为从来没用next.js开发过东西,直接上手代码也是比较难懂,所以先补齐一些概念和因果关系
前置知识
SEO与SSR
SEO全称是Search Engine Optimization
简单来说,就是想办法讨好 Google、百度、必应这些搜索引擎的“爬虫机器人”,让你的网站在搜索结果中排在前面。
如果你的网站排在第一页,你会获得巨大的免费流量;如果排在第十页,基本就没人看了
传统的React使用的是CSR模式,也就是说必须要用户点击进去然后等待js去加载信息,这对搜索引擎的爬虫是很不友好的
为了效率,爬虫必须有一个等待时间,一旦这个时间一过,就爬取不到你想展示的信息了
那么是怎么解决这个问题的,也就是采用新的渲染模式SSR
这个模式干了什么呢,总的来说就是解决渲染太慢的问题,现在我们的数据不用丢到浏览器,再让js一点点渲染出来了,现在我们直接让服务器在后端渲染出html丢给浏览器解析
但这个时候又诞生了一个比较难的技术难题,也就是Hydration(水合),里面的技术比较高深,这里随便说说一笔带过,也就是说现在服务器返回html后,我们的react组件还必须解析一遍这个html然后生成一个虚拟树,这是一个比较耗时耗空间的事情
为了解决这个问题,react团队又开发了新技术RSC
RSC
React 18引入了React Server Components(React 19中稳定)。与传统SSR不同,ServerComponents的代码永远不会下载到浏览器 ——它们只在服务器执行,输出结果发送给客户端,不需要Hydration,这样可以使用庞大的依赖库(如数据库驱动)而不影响前端性能
简单来说,就是不用交互的组件不会发给react比对,而是直接在服务端执行,比如数据库连接这个操作
需要注意是
RSC 实际上并不直接返回纯 HTML 字符串给 React,而是流式传输一种特殊的序列化数据(类似 JSON)。
当浏览器收到这个流时:
- Next.js 框架把这个数据解析成 DOM 节点,直接插入页面。
- React 只需要在那些标记了“这是客户端组件”的占位符(Slots)位置,启动它的逻辑
Server Actions
这个技术与前面两个技术碰到的难题没什么关系,他是为了解决另一个问题,就是常说的胶水代码
试想我们之前在写flask,express,spring……这种后端框架的时候,比如我们要实现一个api端点
我们要先在后端创建一个端点app.route('/api/dosomething')
然后我们在写前端的时候,想和这个api进行交互,我们又得在js代码写一个fetch('/api/dosomething'),这期间又涉及到json等数据的转换处理
这样的写法本身没有任何业务价值,纯粹是为了让前后端能说话
那么这个React 19以后引入的新技术Server Actions是怎么做的呢
原本的做法是,用户点击ui->调用fetch->规范请求数据->请求后端api->调用后端函数->规范返回数据->用户获得响应数据
那么现在的做法就是用户点击ui->直接调用导入的后端函数->后端函数执行->用户看到最新的数据
这样的做法不仅大大简化了开发,还解决了一个长期以来比较头痛的问题,比如用户点击ui让后端执行写入数据库后,前端如果不写一个强制刷新,是看不到最新数据的,强制刷新又意味着要把整个html重新加载一遍,比较浪费,而react的做法是可以根据用户行为更新后端并且局部更新ui,这样就非常巧妙
这项技术是在2023年公布的,还诞生了一个一语成箴的故事
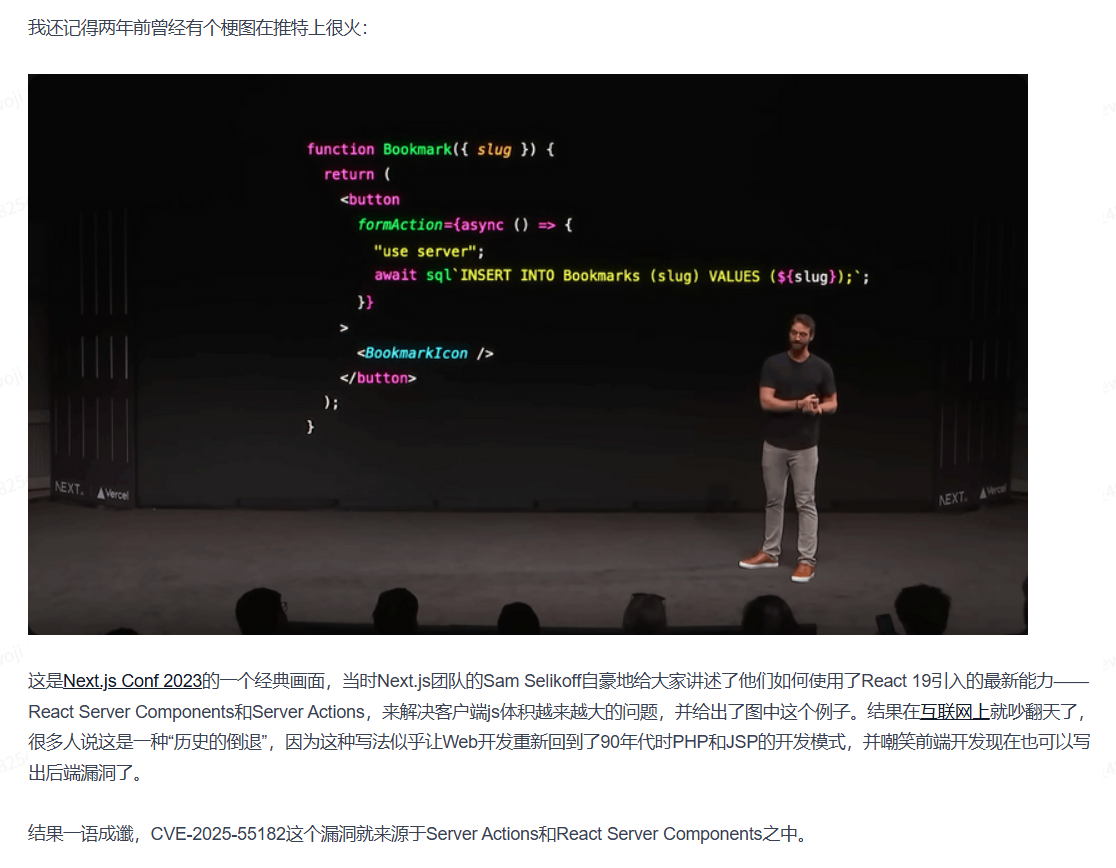
Filght协议流
前面说到RSC的渲染模式的时候,是通过一系列反序列化和序列化流去做的,比如
如果你打开浏览器的 Network 面板,查看 Next.js 的请求,你会看到类似这样的怪异文本流:
1 | M1:{"id":"./src/app/like-button.js","chunks":["client-chunks"],"name":"default"} |
- J0: 代表服务器渲染好的 HTML 结构(类似 JSON 描述的 DOM)。
- M1: 代表一个“引用”。告诉浏览器:“这块地方我渲染不了,这是个 Client Component,请你去加载
like-button.js这个文件来渲染它。”
这就是反序列化的过程: 浏览器收到这串文本 -> React 解析器逐行读取 -> 将其还原为 React 组件树 -> 插入页面。
Server Actions返回值也是这样的序列化值,才可以局部的渲染改变组件
漏洞分析
也就是说早在这项技术公布之初,就有很多开发者预知了会出现漏洞的问题,毕竟这项技术涉及到了反序列化,调用后端代码如此敏感的操作,作为一名安全从业者对此应该更加敏感
功能实现源码分析
函数调用点
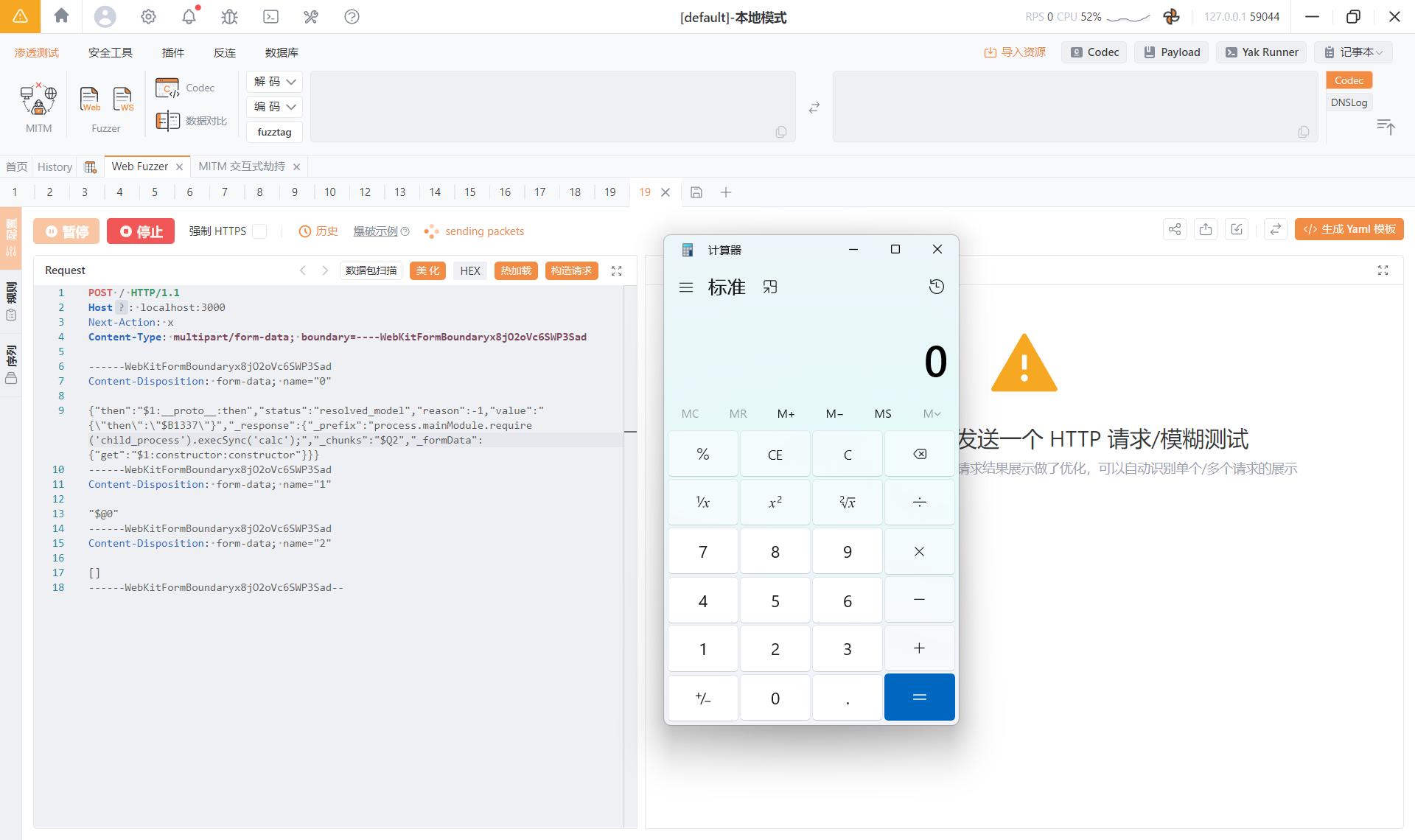
下面简单复现一下使用POST请求直接调用后端函数的功能
比如后端运行前端点击一个按钮让后端弹出计算器
1 | ///app/actions.js |
前端
1 | ///app/page.tsx |
然后在前端点击这个按钮就可以弹出计算器
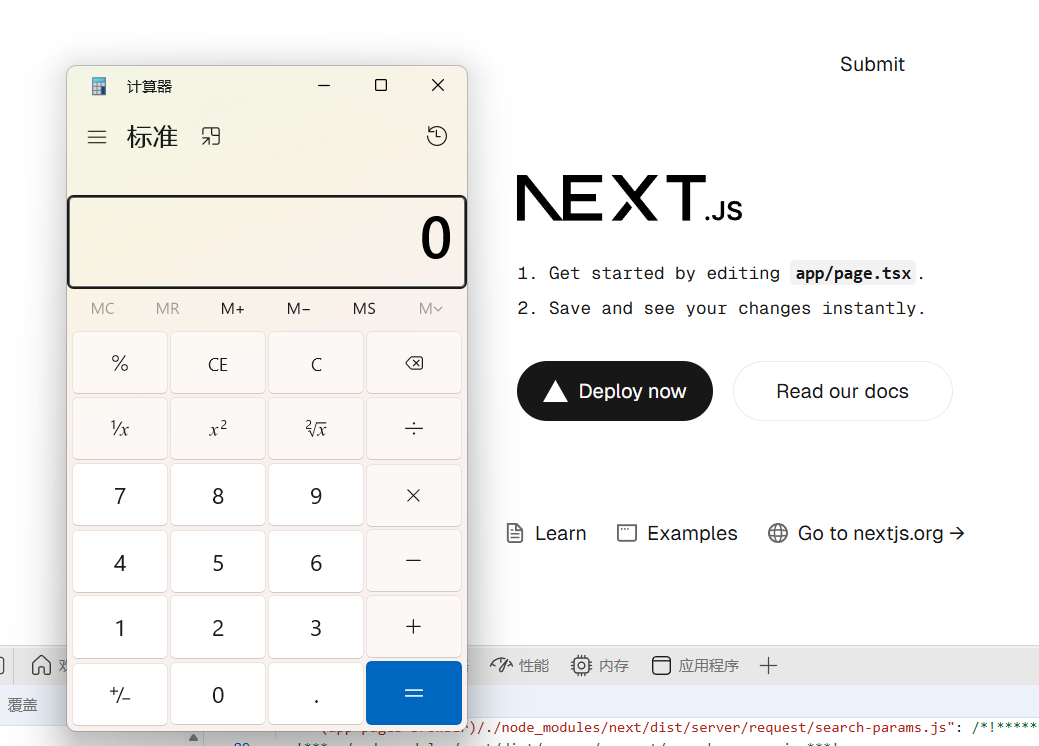
我们来抓包看看这整个过程是怎么发生的
点击submit会抓到这样一个包
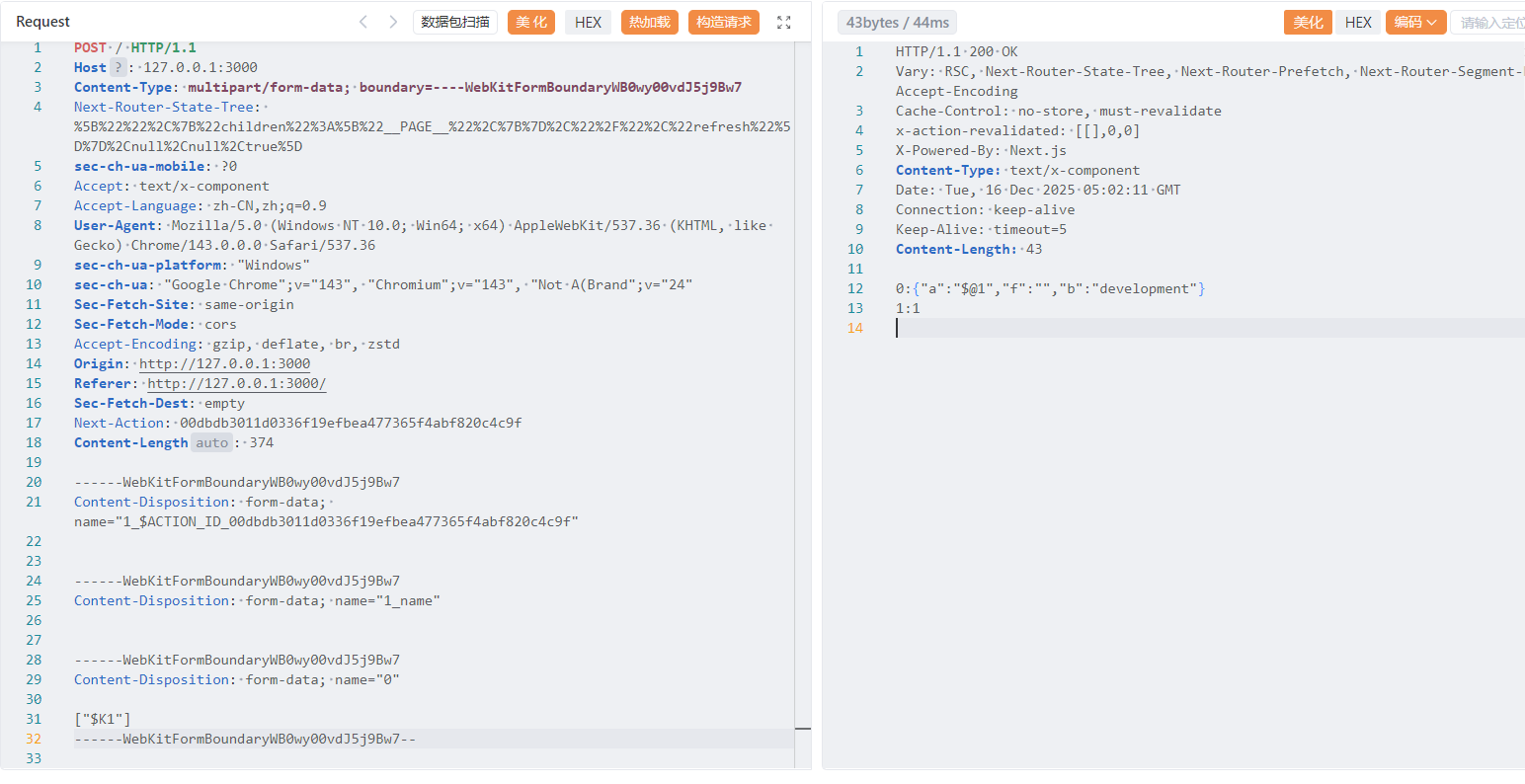
每发一次包就会调用一次后端弹计算器的函数,我们从源码看看是怎么从解析我们这个数据包到调用后端函数的
在next/dist/src/server/app-render/action-handler.ts的getServerActionRequestMetadata位置下断点,这是解析Server Actions的入口点:
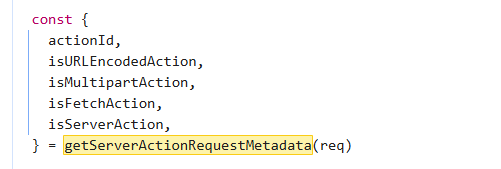
这里使用这个函数从数据包中解析这些选项,看看这个函数具体逻辑
继续跟进可以发现这个函数位于这个文件
import { getServerActionRequestMetadata } from '../lib/server-action-request-meta'
实现逻辑如下
1 | export function getServerActionRequestMetadata( |
这里请求头必须要满足isServerAction的条件才能调用后端函数,其中各个参数表示如下
actionId :从HTTP header中拿到要执行的Server Action
isURLEncodedAction :请求方法是POST且请求包Content-Type是application/x-www-form-urlencoded
isMultipartAction :请求方法是POST且请求包Content-Type是multipart/form-data
isFetchAction :请求方法是POST且actionId不为空
isServerAction :isURLEncodedAction、isMultipartAction、isFetchAction这三个有一个是true
首先看这个actionId,也就是表示我们后端注册的函数的唯一标识是怎么传入的

也就是从我们的请求头Next-Action传入
一旦被解析为是一个ServerAction请求就可以继续往下执行
我们接着一直步过执行直到计算器弹出来
可以看到最后在这个语句,我们的函数被执行了
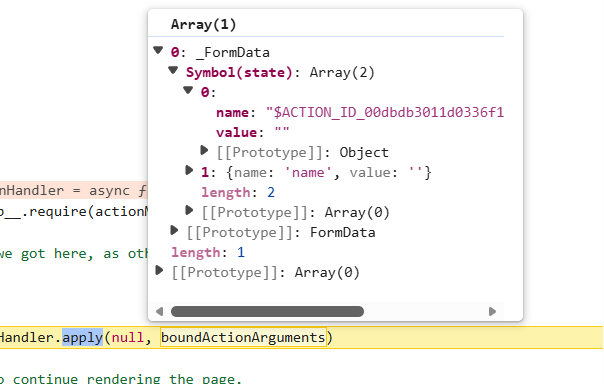
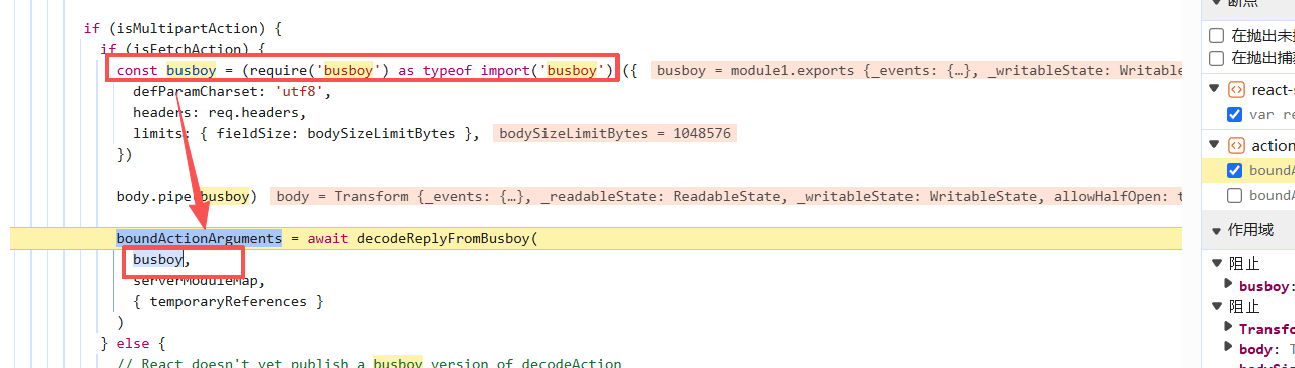
1 | const returnVal = await actionHandler.apply(null, boundActionArguments) |
这个actionHandler.apply函数就是真正调用后端函数calc的地方,只需要传入actionid和值
至于怎么调用的不深究,这个漏洞的调试也不涉及到后面函数调用的步骤
参数传入解析
先往上找到actionid传入的地方,那么就要找boundActionArguments是怎么被赋值的
boundActionArguments有几处被赋值的位置,但是在我们现在传入包的情况只走一个地方,也就是调用decodeReplyFromBusboy来赋值
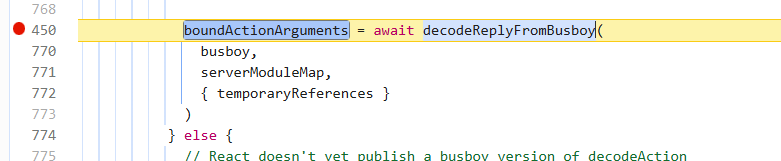
具体逻辑如下
1 | exports.decodeReplyFromBusboy = function ( |
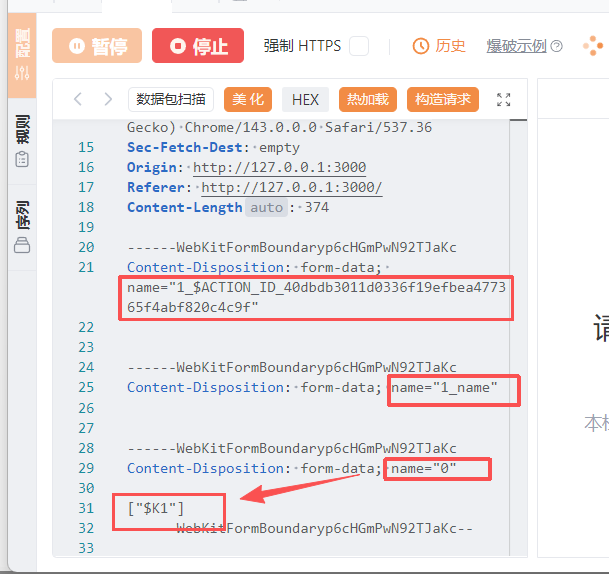
这里的逻辑非常重要,他是用来处理在服务端解析 multipart/form-data 请求流,前面写的例子比较简单,实际上这其中是可以有数据传递的,比如这里可以读取参数
1 | 'use server' |
比如我们按照一定的格式传参,这个格式也就是之后和之前都提到的Flight协议
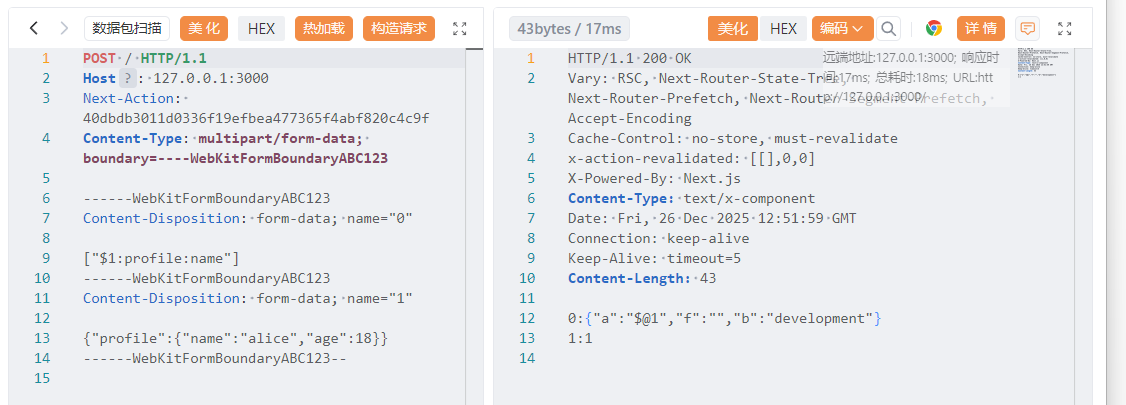
后台是会把formData流的数据输出出来的
整个从前端直接调用后端函数的大概逻辑就是这样
既然要从http传递数据到后端程序调用,那么就肯定会涉及语言变量类型还原的过程
下面具体分析nextjs是怎么处理从http的multipart/form-data数据到javaScript数据类型的还原的
javaScript数据类型还原
先看传入的第一个参数busboy,也就是用来解析我们数据包的库
busboy
NodeJS + Express + busboy 实现图片上传接口并回显前言 在准备之前 可以先简单了解以下busbo - 掘金
简单来说,它的作用就是处理文件上传。它的特点是快且内存占用低,因为它不会把整个文件读入内存,而是像流水线一样一点点处理数据。
这是 busboy 的基础用法指南:
核心工作原理
busboy 的工作流程就像是一个分拣员:
- 输入:HTTP 请求流 (
request) 进入busboy。 - 分拣:
busboy识别出这是普通文本字段(Field)还是文件(File)。 - 输出:通过事件(Events)将解析出的数据抛给你处理。
用法实例
1 | const http = require('http'); |
resolveField
上面可以知道busboy是通过busboy.on("field",回调函数)去处理我们传入的非文件字段
在这里我们跟进它的回调函数

这段代码是为了处理异步传输下可能出现的错误,这里如果有文件正常上传,则把我们的字段缓存,如果没有文件在上传,则直接处理我们的字段,也就是进入resolveField
下面看看resolveFiled是如何处理我们上传的字段的
先看传入的参数,这里传入的键值对其实就是我们http包中每个块的键值对
我们跟进函数,这里只有当值不为空的时候,才会继续处理我们传入的块,也就是调用resolveModelChunk函数

也就是说现在之后处理我们传入的第三个块
接着会进入initializeModelChunk函数继续处理我们传入的值
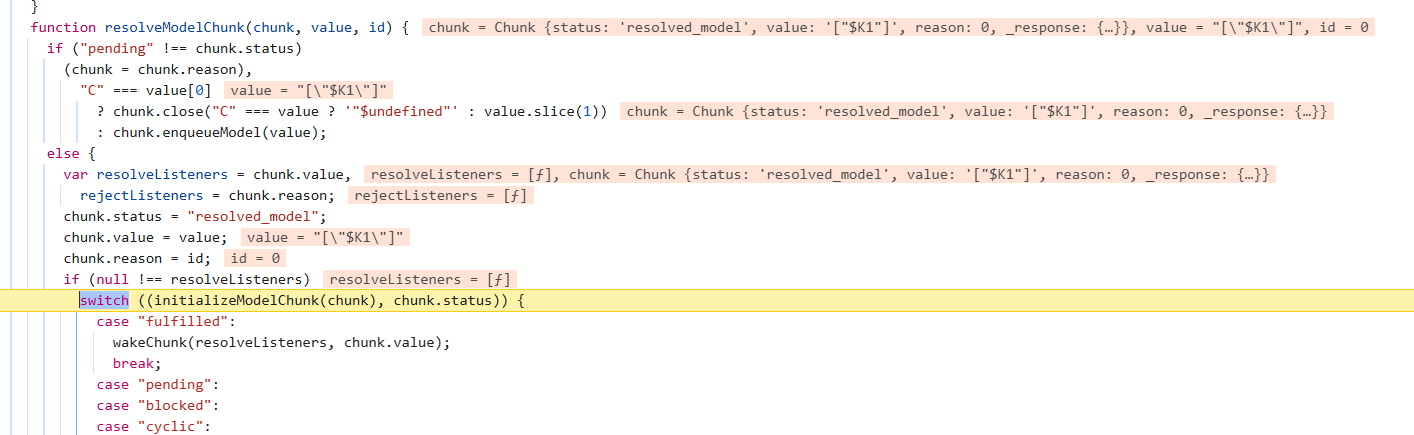
这里分析这个块的状态后,发现是没有完成解析的块的话,则开始还原对象,进入reviveModel函数
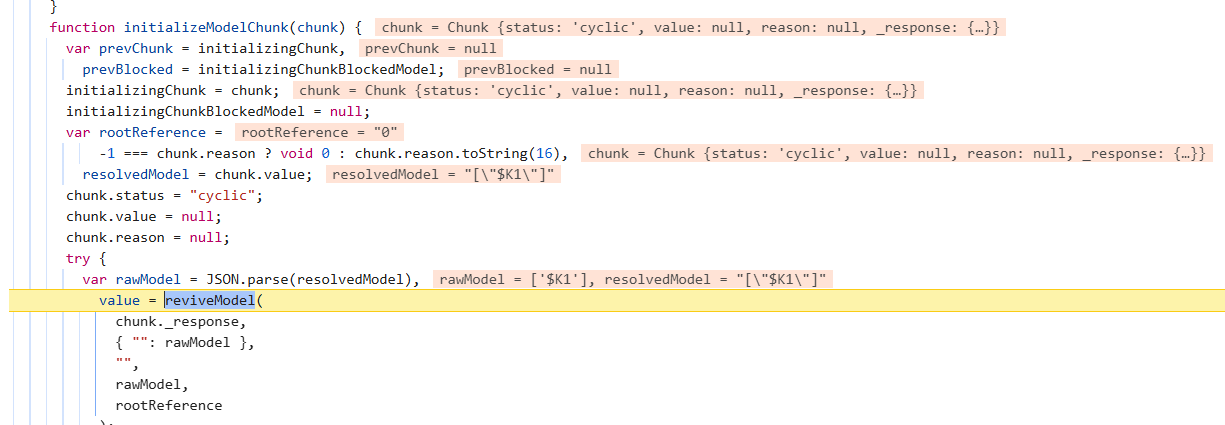
检测到如果传入的值是字符串的话,则使用parseModelString函数进行还原
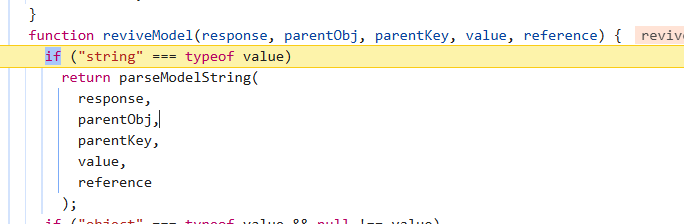
接着就到我们的字符串->JavaScript对象的还原过程了,这里依靠的就是上文提及的Flight协议进行的通信还原
这里整个协议的反序列化比较多,放出部分,可以在这个图中看到一些特殊的符号,比如$,@,Q,K等
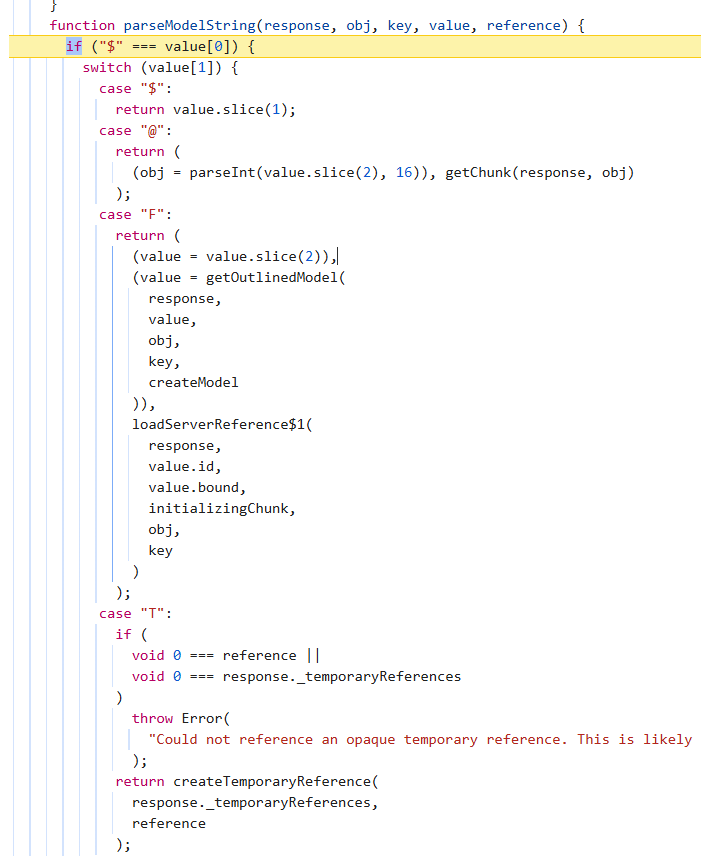
这些都是协议的特殊符号,我们看看这些符号的用途,以及对应的解析方式
基础类型
| 编码格式 | 类型 | 示例 | 解析结果 |
|---|---|---|---|
$$... | 转义字符串 | “$$hello” | “$hello” |
$undefined | undefined | “$undefined” | undefined |
$Infinity ($I) | 正无穷 | “$I” | Infinity |
$-Infinity | 负无穷 | “$-Infinity” | -Infinity |
$-0 | 负零 | “$-0” | -0 |
$NaN ($N) | NaN | “$N” | NaN |
$D... | Date | “$D2024-01-15T00:00:00.000Z” | new Date(…) |
$n... | BigInt | “$n12345678901234567890” | BigInt(“12345678901234567890”) |
引用类型
| 编码格式 | 类型 | 示例 | 解析方式 |
|---|---|---|---|
$<id> | Chunk 引用 | “$1”, “$a” | getOutlinedModel(id) - 获取另一个 chunk 的值 |
$@<id> | Promise | “$@1” | getChunk(id) - 返回 chunk 本身(类 Promise) |
$F<id> | Server Reference | “$F1” | loadServerReference() - 服务器函数引用 |
$T | Temporary Reference | “$T” | createTemporaryReference() - 临时引用 |
$Q<id> | Map | “$Q1” | getOutlinedModel(…, createMap) |
$W<id> | Set | “$W1” | getOutlinedModel(…, createSet) |
$K<id> | FormData | “$K1” | 从 backing store 重建 FormData |
$i<id> | Iterator | “$i1” | getOutlinedModel(…, extractIterator) |
二进制类型
| 编码格式 | 类型 | 字节/元素 |
|---|---|---|
$A<id> | ArrayBuffer | 1 |
$O<id> | Int8Array | 1 |
$o<id> | Uint8Array | 1 |
$U<id> | Uint8ClampedArray | 1 |
$S<id> | Int16Array | 2 |
$s<id> | Uint16Array | 2 |
$L<id> | Int32Array | 4 |
$l<id> | Uint32Array | 4 |
$G<id> | Float32Array | 4 |
$g<id> | Float64Array | 8 |
$M<id> | BigInt64Array | 8 |
$m<id> | BigUint64Array | 8 |
$V<id> | DataView | 1 |
$B<id> | Blob | - |
流类型
| 编码格式 | 类型 | 说明 |
|---|---|---|
$R<id> | ReadableStream | 通用流 |
$r<id> | ReadableStream (bytes) | 字节流 |
$X<id> | AsyncIterable | 异步迭代器 |
$x<id> | AsyncIterable (返回值) | 带返回值的异步迭代器 |
上面这些编码格式中的<id>就是其他Chunk的引用,Flight通过这样的方式来把我们传入的字符串还原为JavaScript的对象
原型链污染点
在上面Flight协议的数据类型中,我们可以注意到一个比较有趣的类型叫做引用类型,这就是我们触发原型链污染的关键
我们先来讨论块与块之间的引用,前面说过http传入multipart/form-data是以一个个块传入的
$N 引用语法
Flight 协议使用 $ 前缀加数字表示对特定 chunk 的引用,冒号分隔的路径用于访问嵌套属性:
"$1": 引用 chunk1 本身"$2:fruitName": 引用 chunk2 解析后对象的fruitName属性"$3:user:email": 引用 chunk3 中的.user.email
Flight 数据解析流程
假设客户端发送如下请求体:
1 | ------WebKitFormBoundaryABC123 |
可以看作:
1 | chunks = { |
解析过程:
1 | "$1:profile:name" |
漏洞的核心问题在于:路径解析逻辑未通过 hasOwnProperty 限制可访问的属性范围,导致攻击者可以沿原型链访问任意属性,包括 __proto__、constructor 等敏感属性。
下面我们去找到原型链污染点
实际上在上面提到的还原对象中,有一个非常危险且可以造成原型链污染的地方
1 | // packages/react-server/src/ReactFlightReplyServer.js |
但是这里使用了hasOwnProperty.call做了防范,所以构不成原型链污染
我们继续往下找看看有没有符合a[b]b或者a可控的地方
回到initializeModelChunk,初始化chunk后如果chunk的状态为fulfilled则调用wakeChunk

往下跟进,对listeners进行回调

在回调中进行上面提到的元素遍历,类似路径遍历的做法去找到某个对象中的属性
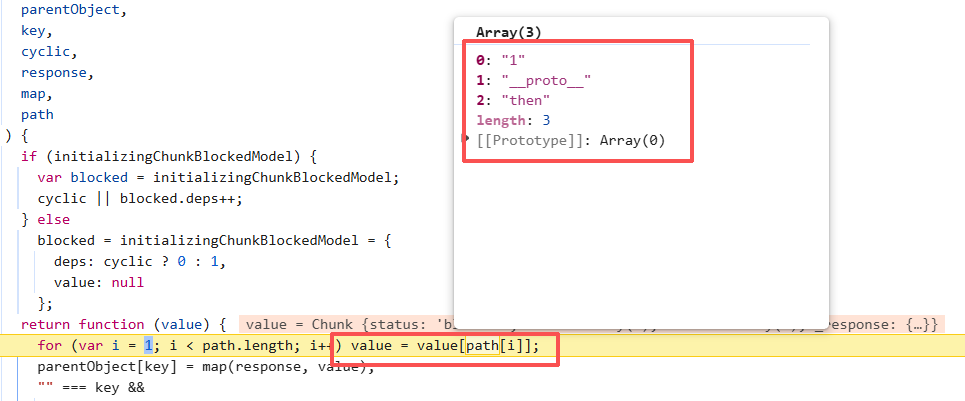
这里就是我们真正的原型链污染点了
漏洞利用
上面提到我们要想进入wakeChunk,就必须要在initializeModelChunk执行返回chunk的状态为fulfilled,一步步跟进代码,发现只有chunk1引用chunk0的时候触发回调,才会进入fulfilled的逻辑
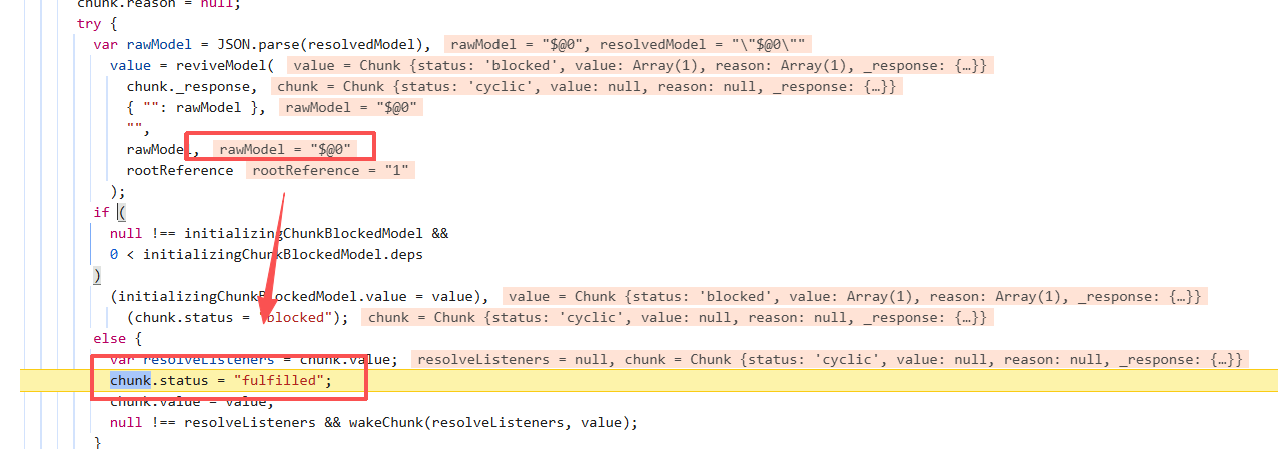
所以我们第二个chunk需要是对第一个chunk的引用,如下
1 | ------WebKitFormBoundaryx8jO2oVc6SWP3Sad |
下面的分析需要提前了解什么是thenable
或者记住一句话await后的代码结束后会执行then方法
我们这里是可以成功污染chunk的属性,自然要对chunk进行分析,首先这个chunk本身是一个thenable对象
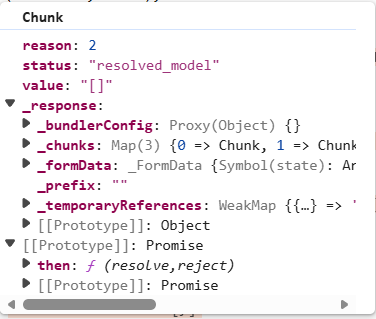
可以看到chunk的原型对象中就存在一个then方法

它的then方法就是我们刚刚执行initializeModelChunk,这也解释了为什么我们使用busboy解析数据包后,可以去进行一个Flight协议的解析,然后进行一些块与块直接的引用
回到我们上面的分析,如果我们把块的status定为resolved_model,那么就会调用 initializeModelChunk → reviveModel,到我们比较熟悉的协议解析,在解析B的时候,有如下操作
1 | case "B": |
此时我们的chunk0是
1 | ------WebKitFormBoundaryx8jO2oVc6SWP3Sad |
其中get就是我们替换成function的构造方法
所以我们返回的是一个then方法
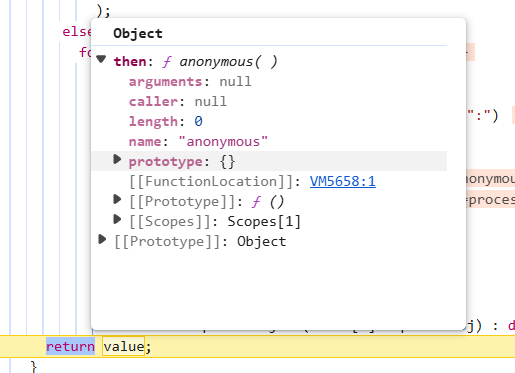
可以在VM5658看到我们临时生成的函数

自此then被执行从而导致RCE
最后贴一个由科恩实验室发布的漏洞文章中的一个非常明了的流程图

官方修复
官方在 ReactFlightReplyServer.js 等核心文件的反序列化逻辑中增加了严格的检查
- 引入
hasOwnProperty检查: 在解析对象属性时,React 现在会强制检查该属性是否为对象自身的属性(Own Property)。代码不再直接通过value[key]访问属性(这会触发原型链查找),而是使用类似Object.prototype.hasOwnProperty.call(value, key)的机制。- 修复前: 攻击者可以通过
__proto__将then或constructor等属性注入到对象原型中。当 React 访问这些 key 时,会沿着原型链向上查找到被污染的属性。 - 修复后: 由于
then或constructor通常不是数据对象自身的属性(而是继承自原型的),hasOwnProperty检查会失败,React 拒绝解析这些恶意注入的属性。
- 修复前: 攻击者可以通过
- 禁止特殊属性访问: 明确禁止了对
__proto__、constructor或prototype等敏感字段的解析和赋值操作,直接从根源上阻止了攻击者构造出Chunk0.value["then"] = Chunk.prototype.then这种恶意结构。
后话
这个漏洞还是比较复杂的,复现难度也不低,基本都是跟着p牛的思路走的,还是比较有成就感,虽然也不是百分百搞懂了,如有错误,恳请指出